1. CNN (Convolutional Neural Network; 합성곱 신경망)
1-1. Region Feature
일반적으로 Machine Learning에서 Data Independence (Input data는 independent(독립적) of each other) 가정이 있다. 그런데, 일반적인 Independent Variable (독립 변수)와 달리, image의 각 pixel은 dependent (종속적) of each other이라는 것을 알 수 있다. (한 pixel이 하얀색일 때, 바로 옆에 있는 pixel이 갑자기 빨간색이기보다는 하얀색일 확률이 높을 것을 생각해보면 좋을 것 같다.)
CNN 이전에, 독립적이지 않은 image의 2차원 pixel 값을 Flatten 해 Input으로 사용해 왔다. 이때, 서로 가까운 위치에 있는 pixel 정보 (ex) 한 pixel이 하얀색이면, 가까운 위치에 있는 pixel도 하얀색이 확률이 높을 것이라는 정보)를 반영하지 못한다. (즉, Information Loss가 발생한다.) 이러한 Region Feature (Graphical Feature)를 학습하고자 등장한 신경망 구조가 CNN이다.
1-2. CNN
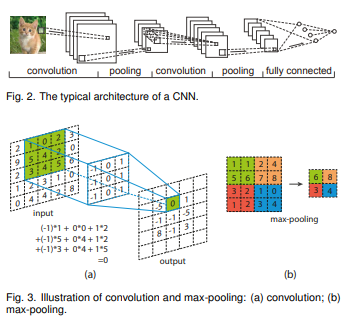
CNN은 Region Feature (Graphical Feature)를 학습시키기 위한 신경망 모델로,
기본적으로 Input Layer, Region Feature를 추출하기 위한 Convolution Layer, Feature Dimension Reduction을 위한 Pooling Layer, 최종 Classification을 위한 Fully Connected Layer, Output Layer로 구성되어 있다.
1) Convolution Layer
Filter (Receptive Field)가 이미지를 Scan하면서 이미지의 Region Feature를 추출
추출한 Feature를 Feature Map (or Activation Map)이라 부름
Input data Weight 합성곱 연산하면서 이때, Weight는 고정된 값이 아니라 학습하면서 바뀌는 값
이미지를 잘 분류할 수 있도록 Feature를 추출해내는 Weight를 학습하는 것임.
2) Stride
3) Padding (Zero Padding)
4) Weight Sharing
한 이미지에서 Filter를 옮길 때마다 같은 Weight를 사용
5) Pooling (Subsampling) Layer
- Max Pooling / Average Pooling
Feature Size를 줄여줌 (a method that reduces data size by selecting a subset of the original data)
학습 속도를 향상시키기 위해Feature Size를 줄여줌
다만, Feature의 Dimension을 축소하다 보니 Information Loss가 발생할 수밖에 없음
그래서 최근에는 Pooling Layer를 사용하지 않는 경우(더 많은 Feature를 학습시킬 수 있으니까)도 있음
6) Fully Connected Layer
Pooling Layer를 통과하고 출력된 Feature를 Flatten 해 Input으로 사용해 학습하는 Layer
Filter크기, Stride, Pooling 종류, Layer 쌓는 횟수 등 모두 사용자가 지정해야 하는 hyperparameter... trial를 계속하면서 최적의 hyperparameter를 찾는 수밖에..
A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
Artificial Intelligence has been witnessing a monumental growth in bridging the gap between the capabilities of humans and machines…
towardsdatascience.com
Convolutional Neural Networks Explained — How To Successfully Classify Images in Python
A visual explanation of Deep Convolutional Nets with a complete Python example that teaches you how to build your own DCNs
towardsdatascience.com
2. Data Augmentation (데이터 증강)
2-1. Data Augmentation이란?

복잡한 model를 만들기 위해 다량의 data가 필요한데, 우리가 갖고 있는 data는 한정적이다. 이를 보완하기 위한 방법이 Data Augmentation이다. Data Augmentation은 data를 임의로 변형해 data 수를 증가시키는 방법이다. 일반적으로 Image Classification Problem에서 Data Augmentation 할 경우 성능이 소폭 상승한다고 알려져 있다.
2-2. Data Augmentation 기법 종류
1) Random Flip : 이미지를 랜덤 하게 좌우 또는 상하 반전
| RandomHorizontalFlip([p]) | Horizontally flip the given image randomly with a given probability. |
| RandomVerticalFlip([p]) | Vertically flip the given image randomly with a given probability. |
| hflip(img) | Horizontally flip the given image. |
| vflip(img) | Vertically flip the given image. |
2) Rotation Flip : 이미지 회전
| RandomRotation(degrees[, interpolation, …]) | Rotate the image by angle. |
3) Crop : 이미지의 일정 부분 자르기
| CenterCrop(size) | Crops the given image at the center. |
| FiveCrop(size) | Crop the given image into four corners and the central crop |
| RandomCrop(size[, padding, pad_if_needed, …]) | Crop the given image at a random location. |
| RandomResizedCrop(size[, scale, ratio, …]) | Crop a random portion of image and resize it to a given size. |
| TenCrop(size[, vertical_flip]) | Crop the given image into four corners and the central crop plus the flipped version of these (horizontal flipping is used by default) |
4) Scaling : 이미지를 확대 또는 축소

5) Cutout
이미지 일부를 사각형 모양으로 검은색 칠하는 기법 (숫자로는 0을 채워 넣기)
6) Cutmix
2개의 이미지를 합치고, 이미지의 Label를 학습시킬 때 위의 그림과 같이, Cat은 0.4, Dog은 0.6으로 Labeling 해 학습을 진행한다.
CutMix is an image data augmentation strategy. Instead of simply removing pixels as in Cutout, we replace the removed regions with a patch from another image.
https://medium.com/@tagxdata/data-augmentation-for-computer-vision-9c9ed474291e
Data Augmentation for Computer Vision
When given enough training data, machine learning algorithms can do amazing feats. Unfortunately, many applications still struggle to…
medium.com
https://paperswithcode.com/method/cutmix
Papers with Code - CutMix Explained
CutMix is an image data augmentation strategy. Instead of simply removing pixels as in Cutout, we replace the removed regions with a patch from another image. The ground truth labels are also mixed proportionally to the number of pixels of combined images.
paperswithcode.com
https://pytorch.org/vision/stable/transforms.html
Transforming and augmenting images — Torchvision main documentation
Shortcuts
pytorch.org
3. CNN Architecture (Network Architecture)
3-1. LeNet
가장 기본적인 CNN 구조로, 32 x 32 크기의 Input, Convolution Layer 2개, Pooling Layer 2개, Fully Connected Layer 3개로 구성되어 있다.
3-2. AlexNet
224 x 224 크기의 RGB 3 Channel Image를 Input으로 사용
ReLU를 Activation Function로 사용, Dropout과 Data Augmentation 등 적용
3-3. VGG
3 x 3 크기의 Convolution Layer를 깊게 중첩한다는 것이 큰 특징
Layer 깊이에 따라 VGG16, VGG19 등으로 불리고 있다.
3-4. GoogleNet (Inception Model; Google + LeNet)
기존 CNN 구조는 Convolution 다음 Pooling Layer를 거치는 것이 일반적인데,
Inception Model은 한 Layer 내에 서로 다른 연산을 거친 후 Feature Map을 다시 합치는 방식이다
이러한 방식으로, 한 Feature Map에서 여러 Convolution을 적용할 수 있므로, 작은 규모의 Feature, 비교적 큰 규모의 Feature를 한 번에 학습할 수 있다는 장점이 있다.
- Global Average Pooling (GAP)
Fully Connected Layer를 Global Average Pooling (GAP)로 대체해 parameter 수를 크게 줄이는 효과
마지막 Feature Map에 대해 각각의 값을 평균내 연결해주는 것 (FC Layer 대비 학습해야 할 parameter 수를 크게 줄일 수 있다)
3-5. ResNet (Residual Network)

- Residual Block
이전 Layer의 Feature Map을 다음 Layer의 Feature Map에 더해준다 (Skip Connection)
Network가 깊어짐에 따라 이전 Layer에 대한 정보는 이후 Layer에서 희석될 수밖에 없는데, ResNet
이러한 단점을 보완하기 위해 이전 정보를 이후에서도 함께 활용하는 것이라 볼 수 있다.
3-6. DenseNet
ResNet의 확장된 버전, ResNet은 이전 Layer와 다음 Layer에 Skip Connection을 적용한 모델이라면, DenseNet은 모든 Layer에 Skip Connection을 적용한 모델이다. (첫 번째 Layer에 대한 정보를 두 번째, 세 번째, ... 마지막 Layer에도 함께 학습 진행)
'AI > ML&DL' 카테고리의 다른 글
| [DL] Is CNN better than RNN for time series data? (0) | 2022.08.23 |
|---|---|
| [Book] 파이썬 딥러닝 파이토치 PART 3 : Deep Learning (0) | 2022.08.19 |
| [Book] 파이썬 딥러닝 파이토치 PART 2 : AI Background (2) (0) | 2022.08.19 |
| [Book] 파이썬 딥러닝 파이토치 PART 2 : AI Background (1) (0) | 2022.08.18 |




댓글